

Vivimos en un mundo dominado por la información. Hoy, quien más información tiene y mayor capacidad de procesarla para convertirla en conocimiento aplicable, es el que obtiene ventajas estratégicas únicas. Ello es posible gracias a las nuevas tecnologías ligadas a la ciencia de datos como el big data, la inteligencia artificial y el aprendizaje automático, entre otras.
De acuerdo con Wikipedia, la ciencia de datos, muy en boga en nuestros días, “es un campo interdisciplinario que involucra métodos científicos, procesos y sistemas para extraer conocimiento o un mejor entendimiento de datos en sus diferentes formas, ya sea estructurados o no estructurados”.
Gracias a estos avances tecnológicos se ha podido procesar y encontrar nuevo conocimiento y hallazgos entre una inmensa cantidad de datos disponibles dispersos y difíciles de procesar. Es el caso del reciente escándalo denominado Pandora Papers, la mayor colaboración de la historia de periodistas de diferentes países para denunciar el uso de paraísos fiscales por figuras públicas y potentados de diferentes lugares del mundo.
Este esfuerzo de investigación, coordinado por el Consorcio Internacional de Periodistas de Investig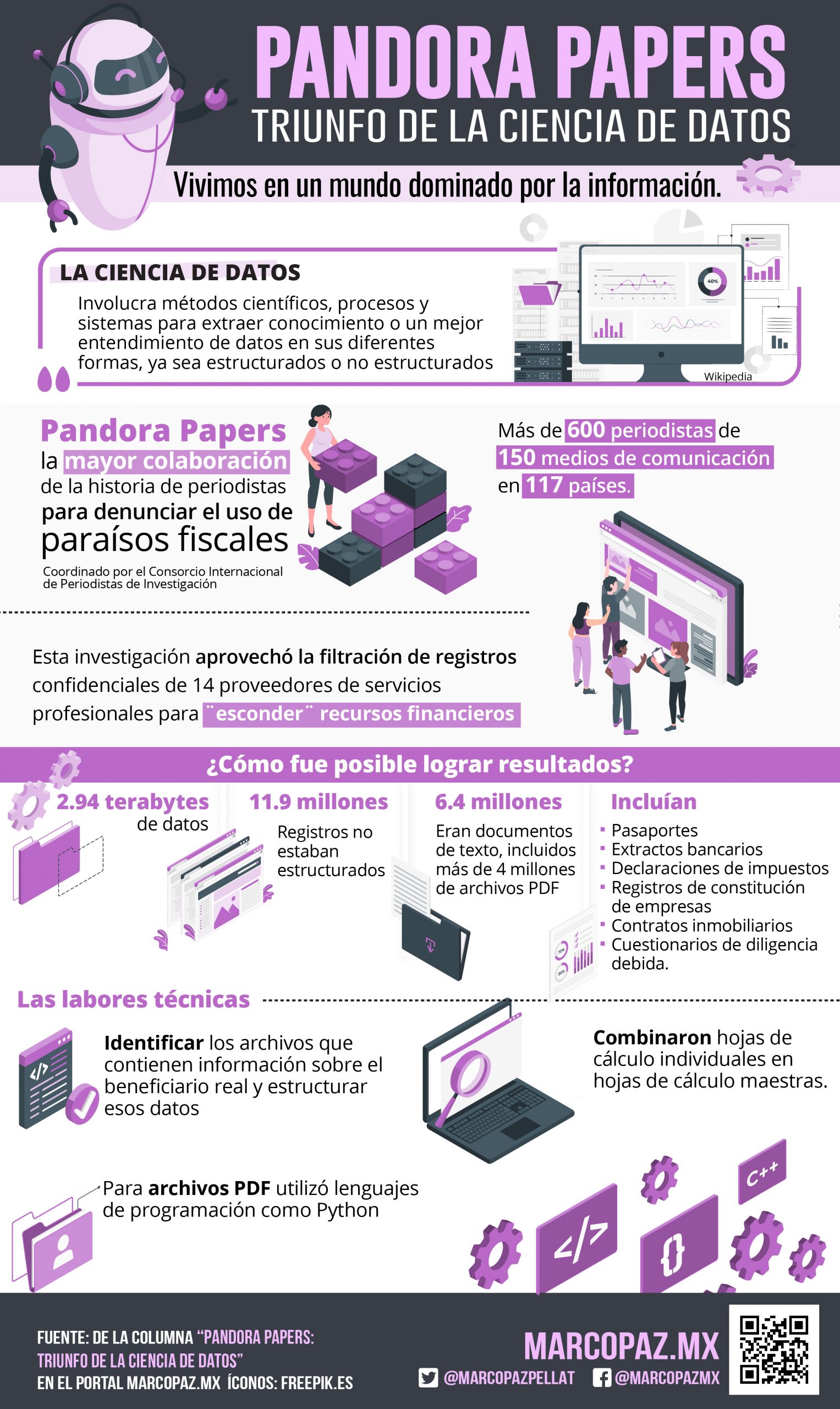 ación (ICIJ por sus siglas en inglés), sumó “a más de 600 periodistas de 150 medios de comunicación en 117 países” (https://bit.ly/3v3nt7u).
ación (ICIJ por sus siglas en inglés), sumó “a más de 600 periodistas de 150 medios de comunicación en 117 países” (https://bit.ly/3v3nt7u).
Esta compleja investigación aprovechó la filtración de registros confidenciales de 14 proveedores de servicios profesionales para ¨esconder¨ recursos financieros a través de compañías fantasmas, fideicomisos, fundaciones y otras entidades en jurisdicciones con impuestos bajos o nulos; que servían a sus clientes para “ocultar sus identidades al público y, a veces, a los reguladores, para abrir cuentas bancarias en países con una regulación financiera ligera”.
¿Cómo fue posible lograr resultados en una andamiaje tan complejo y disperso de información en diferentes entidades y países? Estamos hablando de “2.94 terabytes de datos en forma de documentos, imágenes, correos electrónicos, hojas de cálculo y más. Los más de 11.9 millones de registros no estaban estructurados en gran medida. Más de la mitad de los archivos (6.4 millones) eran documentos de texto, incluidos más de 4 millones de archivos PDF, algunos de los cuales ocupaban más de 10,000 páginas. Los documentos incluían pasaportes, extractos bancarios, declaraciones de impuestos, registros de constitución de empresas, contratos inmobiliarios y cuestionarios de diligencia debida” (https://bit.ly/3BAcQeU).
Las labores técnicas para procesar este mundo de información fue extraordinaria: “Primero, se tuvo que identificar los archivos que contienen información sobre el beneficiario real y estructurar esos datos. Combinaron hojas de cálculo individuales en hojas de cálculo maestras. Para archivos PDF o de documentos, ICIJ utilizó lenguajes de programación como Python para automatizar la extracción y estructuración de datos siempre que fuera posible. Para casos más complejos, el ICIJ utilizó el aprendizaje automático y otras herramientas como los software Fonduer y Scikit-learn para identificar y separar ciertos formularios de documentos más largos.
Después de filtrar y estructurar los datos, la plataforma de investigación Linkurious Enterprise y la base de datos gráfica Neo4j pudieron ayudar a los periodistas a buscar, explorar y visualizar fácilmente esta enorme cantidad de datos¨.
Un triunfo más de la tecnología, en este caso de la ciencia de datos, que nos abre el optimismo sobre las posibilidades de sacarle provecho a la inmensa cantidad de información y datos disponibles en Internet. Este ejemplo puede inspirar a muchos profesionales y expertos. Ojalá que así sea.














